Critical Thinking in the age of AI
When was the last time you thought critically about Large Language Models (LLMs)?
Amidst all of the money, marketing, and hype surrounding LLMs, it’s our responsibility as security professionals to understand the capabilities, limitations, and risks that LLMs present. And while there’s an abundance of writing about “How LLMs are going to solve $PROBLEM”, very little rises to the collective consciousness regarding their inherent limitations.
As such, I’ve been asking questions that “stress test” my own confirmation bias, including:
- What’s happening when LLMs supposedly “reason”?
- How capable are LLMs, really?
- What security impacts are LLMs likely to have?
- What psychological affects does regular use of LLMs have on individuals?
Having asked these questions, I recognize that financial incentives will motivate people’s thoughts and behaviors regarding this new technology 💸 Some individuals will inherently feel the need to push back against the questions, research, and concerns I share in this post as a byproduct of their own confirmation bias.
As Upton Sinclair once wrote:
“It is difficult to get a man to understand something when his salary depends upon his not understanding it.”
And while I believe the technology can (sometimes) be useful, there is a growing body of research highlighting the inherently flawed nature of LLMs—as well as the negative affects they are having on cyber security, critical thinking, and mental health.
But before we get into all of that, let’s establish a baseline—how do LLMs actually work? 🤔
How LLMs actually work: a thought experiment
Instead of spending the next hour watching 3Blue1Brown explain it with all of the technical depth and details behind what makes these “stochastic parrots” function, allow me to save you some time with a thought experiment to understand the important bits.
Try it out for yourself:
Envision a King 💭 What do they look like? Where are they located?
Do you have the picture in mind? Good - hold onto that thought for a moment, because I’m about to open your mind to other possibilities 🧠
- If you’re among the vast majority of readers, you will have envisioned a Caucasian male, somewhere between the ages of 30 and 85, in a palace or a castle like those found in Europe or the United Kingdom.
- Less than 30% of readers will have envisioned an Arabian male, between 40 and 75 years old, with a mustache and goatee (or beard), in a lavish palace with arched doorways and vaulted ceilings.
- A single-digit percentage of readers will have envisioned an African male, between 25 and 65 years old, wearing a leopard skin, located somewhere outdoors on a grassy plain.
- Less than 1% of readers will have envisioned a dark or light colored Chess piece on a checkered board.
What you just experienced is a close approximation to how LLMs actually work. You see—LLMs select tokens with the highest statistical likelihood of appearing in context, based on the training data they’ve been provided and reinforced with. The lower-percentage examples for what people might have envisioned are also a great analogy for why LLMs produce non-deterministic outputs.
Since there can be more than one meaning to a word or phrase, and LLMs retrieve the most likely tokens based on the prompt context and their training data, their output can vary wildly. When it comes to LLMs, statistically significant representation in the training data is King 👑
How LLMs actually work: what the research shows
As I wrote about in a previous blog post, there’s a growing body of research suggesting that LLMs are simply retrieving information directly from their training data.
A recent study from University of Illinois, Urbana-Champaign tested a series of LLMs (including “reasoning” models) for their performance on slightly-modified, novel elementary math and reasoning problems not found in the model’s training datasets. The results were—shall we say—not great 😅
All of the models tested (including OpenAI-o1, Claude 3.7 Sonnet, and DeepSeek R1) failed more than 70% of the time when presented with novel, elementary word problems. What’s more—when presented with questions where there is no correct answer (a fairly reliable way to test for “reasoning” capabilities), the models failed more than 86% of the time!
And by failure I don’t mean that the LLMs stopped working, or merely proclaimed not to “know” the answer—these LLMs provided evidence that they were retrieving formulas and answers from the training data. Here’s one example from the research study
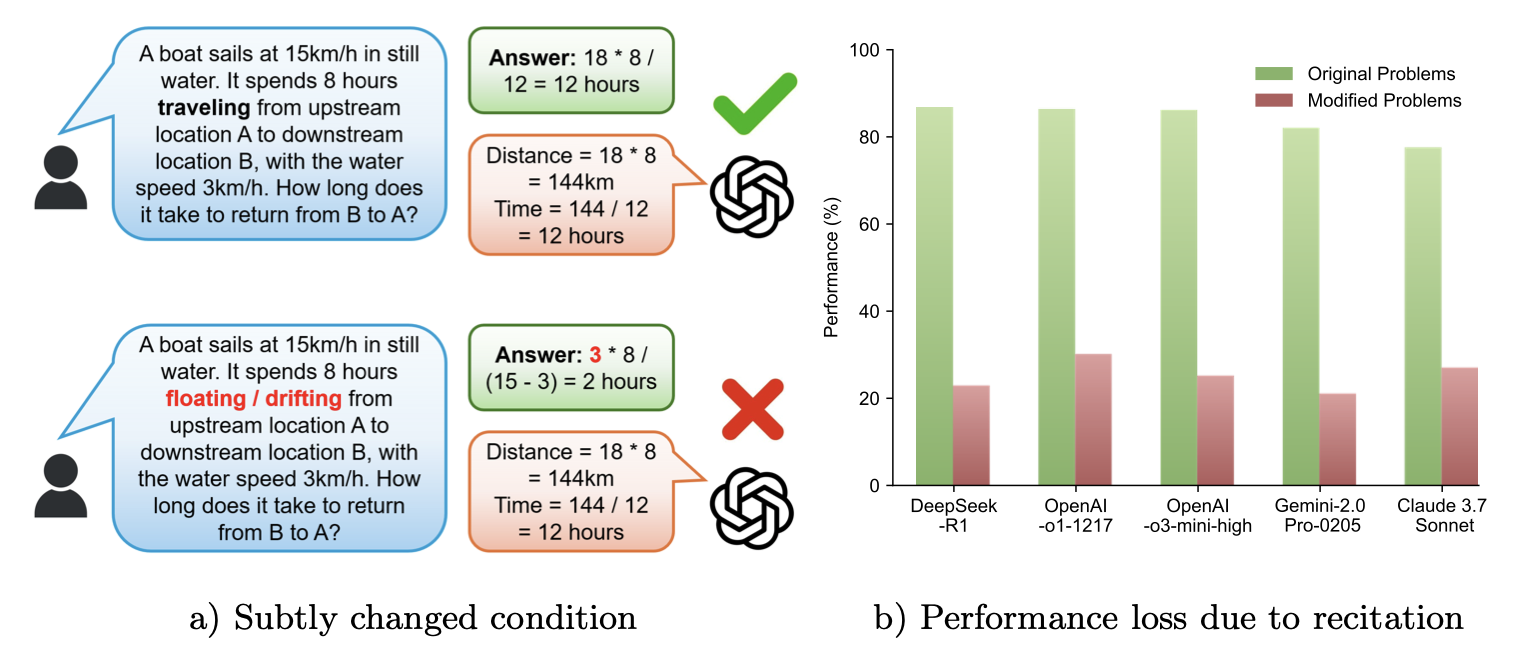 “Recitation over Reasoning” by Yan, et. al.
“Recitation over Reasoning” by Yan, et. al.
So if models—when presented with novel problems—are confidently failing more than 70% of the time, what happens when we apply LLMs to other problems? For example, the increasingly-popular concept of using LLMs as search engines.
The “hallucinations” aren’t bugs—they’re features!
Now that the we’ve been deluged with AI slop, people are using LLMs to filter out the noise when searching for useful information. Unfortunately, as research has shown, the “knowledge asymmetry” of this predicament has led to an increased volume of false information 😞 As 404 Media aptly wrote, welcome to the ‘Fuck It’ era 🤦♂️
So how do we know this is happening? Well, a recent study from the Columbia Journalism Review tested popular LLMs for their ability to search the Internet—including testing LLM search engines with paid versions. The research found that, collectively, LLM search engines confidently provided wrong answers (read: ”hallucinated”) more than 60% of the time.
” by Columbia Journalism Review](/assets/img/ai/confidently-wrong.png) AI Search Has A Citation Problem” by Columbia Journalism Review
AI Search Has A Citation Problem” by Columbia Journalism Review
To make matters worse—according to OpenAI’s internal tests, their latest “reasoning” models “hallucinate” more frequently than their predecessors (the o1 and o1-mini models). At a time when people are increasingly relying on LLMs to help overcome a deluge of AI slop (ironically made possible by LLMs), the last thing we needed were more hallucinations 😩
How will “hallucinations” affect security professionals?
First, allow me to restate the two points I’ve made so far:
- LLMs fail to solve novel problems more than 70% of the time, and have been shown to retrieve (or as Yan et. al. states, “recite”) information directly from training data.
- On average, LLMs fail to correctly identify their source of information more than 60% of the time—and will still “hallucinate” outputs even when provided with sample text that almost-certainly exists in the training data.
Now, what do you think happens when a company’s software developers start using LLMs to generate code en masse 🤔 How secure do you think the codebases are for those company’s who already have 95% of their code written by AI? What happens when an LLM “hallucinates” by trying to import a package that doesn’t exist?
If you’ve been in Application Security for a while then you’ve probably heard of “typosquatting” attacks as a means of introducing malicious packages into an application’s Software Bill of Materials (SBOM). Well, allow me to introduce you to the latest variant: “slopsquatting”:
 by Spracklen et. al.](/assets/img/ai/slopsquatting.png) We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs by Spracklen et. al.
We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs by Spracklen et. al.
The attack vector is so simple, and yet so hard to prevent due to the non-deterministic nature of LLMs—not to mention the sheer number of LLM variants available to software developers today. To make matters worse, attackers can also use LLMs to write malicious packages quickly after registering them—and then create hard-to-detect variants in perpetuity. RIP file hash detection techniques 🪦
By now I’m sure many of you are probably thinking “surely this doesn’t happen that often”, and unfortunately you’d be wrong. Here’s an excerpt from The Register, and a diagram from the paper for reference on how different models perform:
“In a recent study, researchers found that about 5.2 percent of package suggestions from commercial models didn’t exist, compared to 21.7 percent from open source or openly available models” —The Register, LLMs can’t stop making up software dependencies and sabotaging everything
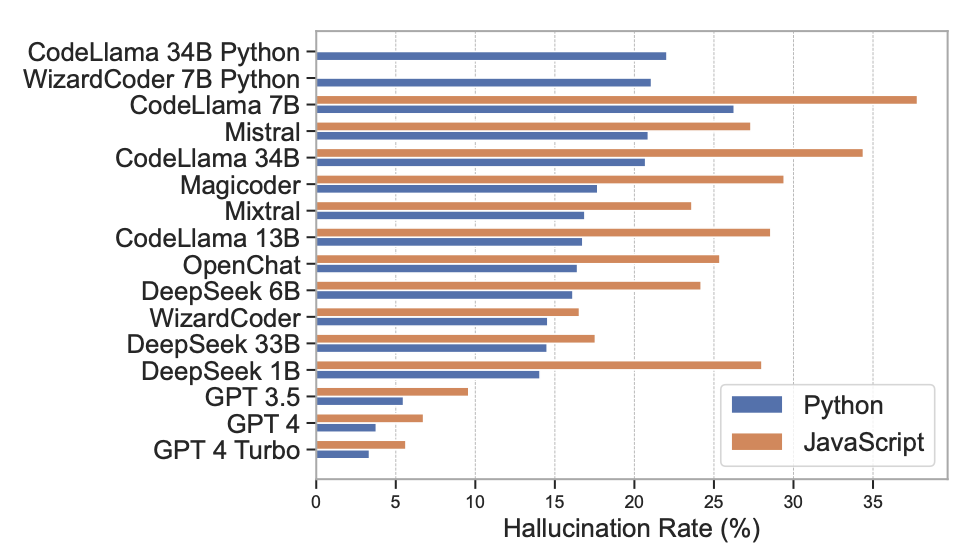 We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs by Spracklen et. al.
We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs by Spracklen et. al.
As security professionals, this is an important trend to pay attention to because we’re about to see a metric-ton of code written by LLMs as businesses push for more reflexive AI usage as a baseline expectation. If your company doesn’t have a robust DevSecOps program in place to prevent security problems from making their way to production, you’re now even more likely to experience a Bad Day **™️ in the future.
And perhaps it’s due to all of the marketing hype—but we are witnessing executives eagerly reach for LLMs as a solution to their businesses problems. Which brings me to my next point.
How do LLMs affect critical thinking?
A joint study between Carnegie Melon University (CMU) and Microsoft recently showed that, if you’re confident in your own knowledge and skills within a given field, you’re more likely to think critically about LLM outputs related to that field 👍
This is generally a positive finding, which reinforces the commonly held belief among technologists that LLMs are more powerful in the hands of experienced professionals. But what happens when LLMs are used to assist individuals with contexts outside their area of expertise?
Unfortunately, LLMs are frequently used to help an individual overcome a knowledge or skills gap—and in some cases, to simply perform cognitive offloading. The CMU and Microsoft study showed that individuals are less critical of LLM outputs when used this way, which is why the LLM failure rates I highlighted above ought to be a point of concern for businesses.
In addition to the CMU and Microsoft study, a study by Dr. Michael Gerlich from the Swiss Business School showed “a significant negative correlation between frequent AI tool usage and critical thinking”. Taken together, these studies paint a grim picture for what the future might look like in a world where AI becomes ubiquitous.
How does prolonged LLM usage affect mental health?
In addition to having negative impacts on critical thinking skills, a joint study from the Massachusetts Institute of Technology (MIT) and OpenAI showed that prolonged use of LLMs correlated with negative psychological outcomes—such as high amounts of loneliness, dependence, and addictive behavior patterns (termed “problematic behaviors” in the study).
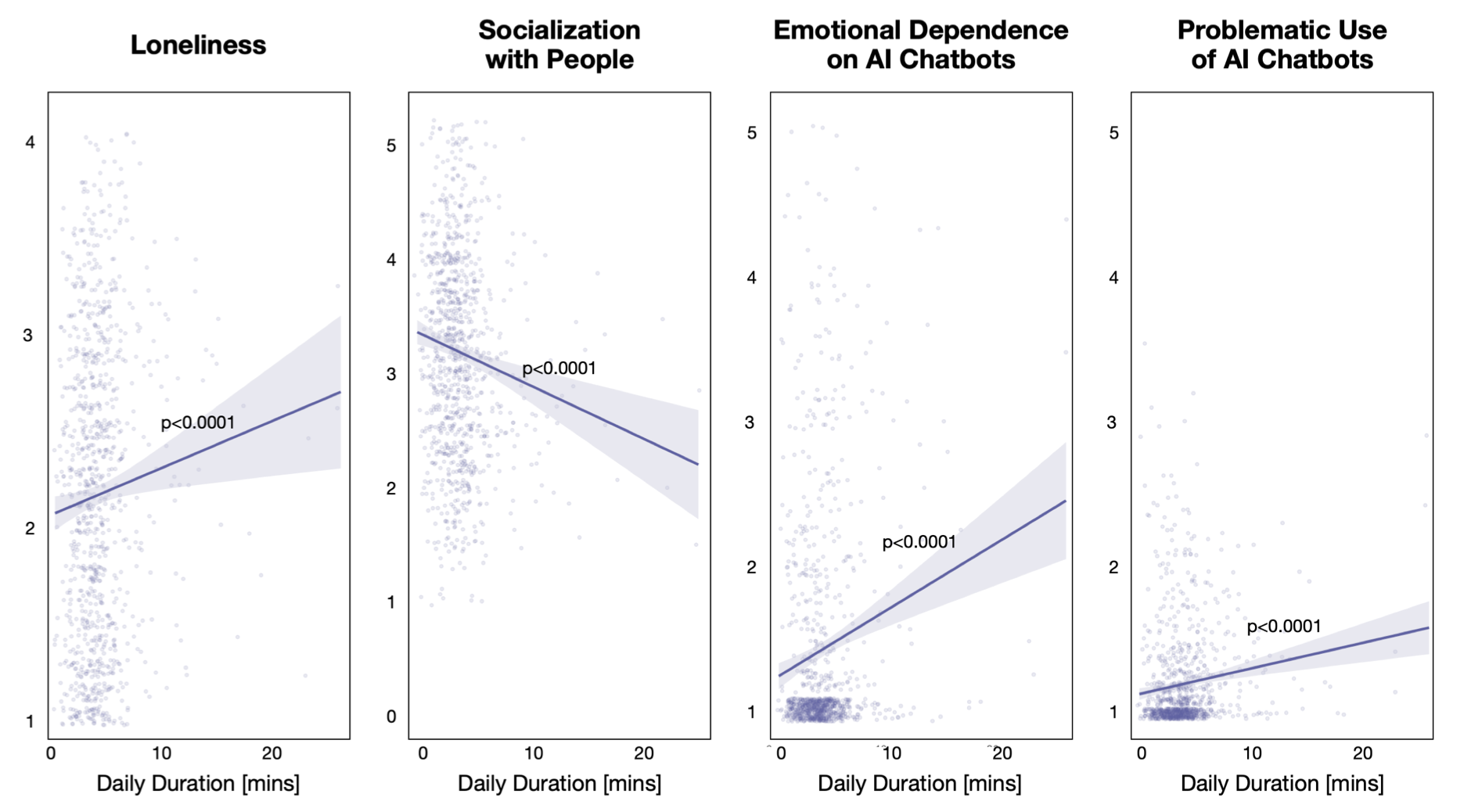 “How AI and Human Behaviors Shape Psychosocial Effects of Chatbot Use” by Fang et. al.
“How AI and Human Behaviors Shape Psychosocial Effects of Chatbot Use” by Fang et. al.
A noteworthy finding from this study was that non-personal topics were associated with greater dependence among users who interacted with LLMs for longer periods of time. This is worth paying attention to, as it clearly aligns with the ways we might expect technical individuals to interact with LLMs as they complete work-related tasks.
Some of the addictive behaviors identified in the study include:
- Procrastination and delaying the completion of necessary tasks due to using the LLM
- Suffering from sleep deprivation due to excessive use of the LLM
- Loss of interest in previously enjoyable activities due to excessive interaction with the LLM
- Experiencing anxiety or irritability when unable to access the LLM
If this study can teach us us anything, it’s that—as an industry already experiencing significant amounts of burnout and substance abuse issues—security professionals ought to be cautious about the degree to which we engage with LLMs.
Taking proactive steps to fortify one’s mental health has always been a good idea—and as LLM usage increases, it will become even more important to remain vigilant against their mental health side effects.
Where do we go from here?
Nicholas Carlini (an incredibly talented and well-regarded AI researcher formerly at Google DeepMind, and now at Anthropic) recently published a blog titled My Thoughts on the Future of “AI”. In the post Nicholas challenges readers to make predictions for what will happen over the next few years regarding the state of AI—and so I thought I’d offer my predictions here on how I believe AI will intersect with (and affect) the Information Security sector.
My predictions for 2028, and their [confidence scores]:
- When tasked with solving novel security problems, LLMs will fail at high rates (>60%) without the assistance of new “gadgets” (read: bolt-on features, tools, protocols, etc.) [92%]
- The amount of public CVEs resulting from AI-generated code will grow exponentially [83%]
- Skill attrition and increased rates of burnout will be experienced by individuals that become overly-reliant on LLMs, leading to an actual skills shortage in the security industry [67%]
Why I’m making these predictions:
After reading the research study from NYU and individuals at XBOW on the performance of LLM Agents tasked with finding security vulnerabilities, I was convinced that LLMs are simply performing retrieval from the training data.
Since then, the more ablation studies and research into LLM reasoning I read, the more convinced I become of this. I get the sense that other leading thinkers in the industry are starting to recognize this as well, and that—between now and 2028—we’ll see a number of “AI for Security” companies pivot to the “human augmentation” approach.
My second prediction is based on two observations: the meteoric rise in “vibe coding”, and my own experiences using GitHub’s Copilot to write code while I was still working there 👀 Given what I’ve read and experienced regarding how LLMs perform “retrieval” (or “recitation”) from their training data—and what we know about how (in)secure open source software is, on average—this prediction feels like a foregone conclusion. Doubly so when we consider that there are already companies who have generated 95% of their code with LLMs.
And finally, my prediction for skill attrition and burnout is based on my own experiences—as well as observations and experiences from my friends in the industry. We’re likely to see more studies performed on the psychological affects of LLMs, which I’ll report back on as I discover and read them. While it’ll be difficult to correlate exactly between psychological affects of LLMs and security industry burnout, I also sort-of hope I’m wrong about this one 🤞😅
In the mean time we’ll have to wait and see how things turn out—but I look forward to reflecting on this post in three years to discuss what happened!
If you found this post interesting or useful, I invite you to support my content through Patreon — and thank you once again for stopping by 😊 While I consider my next blog post, you can git checkout other (usually off-topic) content I’m reading over at Instapaper.
Until next time, remember to git commit && stay classy!
Cheers,